Motto: „În era electronică, este esenţial pentru supravieţuirea unei limbi ca ea să fie folosită în sistemele de informare electronică.” 1
 Uniunea Europeană promovează diversitatea lingvistică şi sprijină multilingvismul privit ca o condiţie indispensabilă pentru exercitarea drepturilor democratice. În acest scop, a fost organizată conferinţa de la Viena pe tema „Viitorul plurilingvistic european în cadrul extinderii Uniunii Europene”, 22-24 noiembrie 2001, la care 150 de experţi din 20 de ţări aparţinând Uniunii Europene ( sau candidate) au formulat o serie de principii privitoare la necesitatea integrării lingvistice. În cadrul unei Uniuni lărgite, convieţuirea nu ar fi posibilă fără existenţa unui liant comun, iar acesta nu poate fi decât limbajul, fundamentul comunicării dintre oameni. Printre principiile de bază ale noii abordări se numără: dreptul tuturor cetăţenilor de a învăţa şi a folosi propria limbă naţională şi limba minorităţilor cărora le aparţin, datoria tuturor guvernelor de a încuraja şi a promova învăţarea limbilor străine prin luarea unor măsuri speciale, chiar şi dincolo de nivelul educaţiei în şcoală etc. Având în vedere toate aceste obiective, Uniunea Europeană îşi propune să dea o atenţie mai mare limbilor ţărilor neglijate în trecut.2
Uniunea Europeană promovează diversitatea lingvistică şi sprijină multilingvismul privit ca o condiţie indispensabilă pentru exercitarea drepturilor democratice. În acest scop, a fost organizată conferinţa de la Viena pe tema „Viitorul plurilingvistic european în cadrul extinderii Uniunii Europene”, 22-24 noiembrie 2001, la care 150 de experţi din 20 de ţări aparţinând Uniunii Europene ( sau candidate) au formulat o serie de principii privitoare la necesitatea integrării lingvistice. În cadrul unei Uniuni lărgite, convieţuirea nu ar fi posibilă fără existenţa unui liant comun, iar acesta nu poate fi decât limbajul, fundamentul comunicării dintre oameni. Printre principiile de bază ale noii abordări se numără: dreptul tuturor cetăţenilor de a învăţa şi a folosi propria limbă naţională şi limba minorităţilor cărora le aparţin, datoria tuturor guvernelor de a încuraja şi a promova învăţarea limbilor străine prin luarea unor măsuri speciale, chiar şi dincolo de nivelul educaţiei în şcoală etc. Având în vedere toate aceste obiective, Uniunea Europeană îşi propune să dea o atenţie mai mare limbilor ţărilor neglijate în trecut.2
Societatea românească trebuie să se adapteze rapid la societatea informaţională europeană. Cum ar fi posibil acest fenomen? În primul rând, prin informatizarea limbii române, demers ce permite promovarea informaţiei cu caracter multilingv şi multicultural. Realizarea unei astfel de comunicări mediate prin tehnologia informaţiei impune metodologii specifice de cercetare şi resurse lingvistice în format electronic: dicţionare online /offline, traducătoare/asistenţi de traducere automată, biblioteci virtuale/electronice etc. Calitatea acestora în conformitate cu standardele europene stabileşte nivelul de tehnologizare al unei limbi naturale.
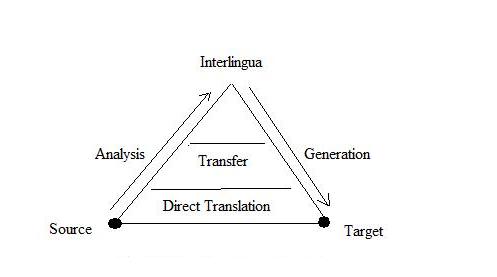 Traducerea automată, unul din visele secolului al XVII-lea, a devenit o realitate abia în secolul al XX-lea, când s-a materializat din punct de vedere tehnic. Traducătorul automat nu este un instrument de investigare intelectuală, ci o aplicaţie a computerului şi a ştiinţelor limbii destinată dezvoltării unui sistem care să răspundă solicitărilor practice.
Traducerea automată, unul din visele secolului al XVII-lea, a devenit o realitate abia în secolul al XX-lea, când s-a materializat din punct de vedere tehnic. Traducătorul automat nu este un instrument de investigare intelectuală, ci o aplicaţie a computerului şi a ştiinţelor limbii destinată dezvoltării unui sistem care să răspundă solicitărilor practice.
Conceptul de machine translation , întâlnit adesea cu acronimul MT, se referă la un sistem computaţional care să poată produce o traducere cu sau fără ajutorul omului, spre deosebire de instrumentele de traducere care ajută traducătorii umani (oferindu-le accesul la dicţionarele on-line, baze de date , transmiterea şi recepţionarea unui text etc). Prin urmare, machine translation este un subdomeniu al lingvisticii computaţionale care cercetează şi propune utilizarea unui software pentru traducerea textelor dintr-o limbă în alta. Tehnica actuală permite substituirea de cuvinte şi nu o receptare a textului care să fie tradus prin interpretare, fenomen ce este specific traducerii umane. Trebuie menţionat faptul că MT-ul s-a dovedit a fi un element util pentru traducătorii umani.
Procesul tehnologic al traducerii automate constă în două etape principale: decodarea sensului gramatical din textul sursă şi recodificarea în textul ţintă. În spatele acestor proceduri, aparent foarte simple, stau operaţiuni complexe. Prima problemă care se pune într-o astfel de situaţie este modalitatea în care faci un computer să „înţeleagă” sensurile.
 În 1996, la Bucureşti, a avut loc Seminarul Naţional pe tema Limbaj şi tehnologie, iar comunicările ştiinţifice prezentate au fost publicate într-un volum cu acelaşi titlu, care croieşte noi direcţii de cercetare pentru lingvistica computaţională. Informatizarea limbii române ( ce include atât procesarea limbajul scris, cât şi procesarea celui vorbit) a constituit una din principalele preocupări ale profesorului Mihai Drăgănescu, care a avut un rol esenţial în ce priveşte apariţia Comisiei de Informatizare a Limbii Române de la Academia Română. Necesitatea existenţei unei astfel de organizaţii s-a dovedit extrem de utilă. Noile principii dezvoltate de membrii acestei comisii sunt, de fapt, concretizarea iniţiativei marelui savant român ale cărui lucrări realizate în urmă cu 25-30 de ani au promovat noţiunile de „societate informaţională” şi „societatea cunoaşterii”.
În 1996, la Bucureşti, a avut loc Seminarul Naţional pe tema Limbaj şi tehnologie, iar comunicările ştiinţifice prezentate au fost publicate într-un volum cu acelaşi titlu, care croieşte noi direcţii de cercetare pentru lingvistica computaţională. Informatizarea limbii române ( ce include atât procesarea limbajul scris, cât şi procesarea celui vorbit) a constituit una din principalele preocupări ale profesorului Mihai Drăgănescu, care a avut un rol esenţial în ce priveşte apariţia Comisiei de Informatizare a Limbii Române de la Academia Română. Necesitatea existenţei unei astfel de organizaţii s-a dovedit extrem de utilă. Noile principii dezvoltate de membrii acestei comisii sunt, de fapt, concretizarea iniţiativei marelui savant român ale cărui lucrări realizate în urmă cu 25-30 de ani au promovat noţiunile de „societate informaţională” şi „societatea cunoaşterii”.
Volumul Limba Română în Societatea Informaţională – Societatea Cunoaşterii, apărut sub tutela Academiei Române, Secţia de Ştiinţă şi Tehnologia Informaţiei, Institutul de Cercetări pentru Inteligenţă Artificială, coordonatori: Dan Tufiş, Florin Gh. Filip, 2002, marchează noile progrese făcute în România în ce priveşte informatizarea limbii române. Secţiunea a II-a, numită, Tehnologii ale limbajului scris relevă câteva aspecte tehnice şi metode de lucru aplicabile pentru algoritmii de segmentare a textului, inserarea automată a diacriticelor în texte, structura statistică de cuvinte, dezambiguizarea automată a cuvintelor din corpusuri paralele, referenţialitate şi cursivitate în relaţie cu structura de discurs.
Progresele făcute în această direcţie nu au eliminat imaginea utopică asupra traducerilor automate, dar au venit în sprijinul unor activităţi din diverse compartimente sociale, economice şi politice. Necesitatea repetării aceleiaşi activităţi birocratice din mai multe domenii este consumatoare de resurse umane şi financiare. Automatizarea transferului de informaţii dintr-o limbă în alta înseamnă un timp de lucru mai scurt.
 Traducerea umană, deşi cu o acurateţe mult mai mare, încetineşte schimbul de informaţii dintr-o limbă în alta. Realizarea instrumentelor de procesare a limbajului natural implică resurse financiare şi temporale care nu necesită consum repetat. Prin dezvoltarea bazelor de date lingvistice, computerul stochează informaţii asupra cărora nu este necesară revenirea prin rememorare. Traducătorul uman este supus memoriei selective şi apelează repetat la documente care să-i reîmprospăteze memoria. Inteligenţa artificială nu are nevoie de astfel de demersuri. Este exclusă învăţarea prin repetare, o informaţie asimilată va fi procesată ca atare, fiind, astfel, îndepărtată ambiguitatea ce apare de multe ori în cazul omului care aplică o anumită informaţie foarte rar.
Traducerea umană, deşi cu o acurateţe mult mai mare, încetineşte schimbul de informaţii dintr-o limbă în alta. Realizarea instrumentelor de procesare a limbajului natural implică resurse financiare şi temporale care nu necesită consum repetat. Prin dezvoltarea bazelor de date lingvistice, computerul stochează informaţii asupra cărora nu este necesară revenirea prin rememorare. Traducătorul uman este supus memoriei selective şi apelează repetat la documente care să-i reîmprospăteze memoria. Inteligenţa artificială nu are nevoie de astfel de demersuri. Este exclusă învăţarea prin repetare, o informaţie asimilată va fi procesată ca atare, fiind, astfel, îndepărtată ambiguitatea ce apare de multe ori în cazul omului care aplică o anumită informaţie foarte rar.
Pe lângă avantaje există, bineînţeles, şi dezavantaje. Perfecţiunea nu este una din caracteristicile traducerii automte şi nu atinge rafinamentul celei umane din textele literare cu diverse nuanţe poetice ce depăşesc analiza computaţională. Cu ajutorul noilor tehnologii este posibilă traducerea manualelor tehnice, a documentelor oficiale, a prospectelor comerciale, a rapoartelor medicale etc. Printre acestea se află, în primul rând, lipsa perceperii diferenţelor semantice întâlnite la foarte multe cuvinte, indiferent de limba ţintă sau limba sursă. Latura artistică este neglijată atunci când e vorba de traducerea automată. Machine translation funcţionează pe baza laturii formale a unei limbi şi, cu cât este mai puţin evident acest aspect, cu atât apar mai multe dificultăţi. Diferenţele lingvistice dintre limbi necesită realizarea unei punţi de legătură, mai exact, reguli de transfer care să faciliteze traducerea.
Dacă limbile engleză, franceză, germană apar foarte des în rapoartele European Association for Machine Translation3, limba română apare doar sporadic. Se pare că până acum nu s-a remarcat prin calitate şi cantitate nici un soft de traducere. Medierea lingvistică ar facilita dezvoltarea unor proiecte din toate domeniile de activitate, fenomen ce poate fi sprijinit prin traducătoare electronice personalizate în funcţie de domeniul de activitate. Dificultăţile lingvistice ar putea fi soluţionate mult mai uşor, chiar dacă este vorba de limbi din familii diferite. Sistemul flexionar bogat al limbii române presupune un efort suplimentar pentru constituirea bazelor de date lingvistice, dar, în acelaşi timp, elimină ambiguitatea semantică. Cu cât sistemul flexionar este mai bogat, cu atât ambiguitatea este mai mică, întrucât nu există forme flexionare identice care să exprime valori gramaticale diferite (evident, cu câteva excepţii). Raportul dintre cele două este invers proporţional.
Considerăm că este necesară, totuşi, continuarea metodelor tradiţionale de studiu propuse de lingviştii români, dar şi receptarea inovaţiilor din lingvistica matematică şi inginerească. Lingvistica generală reclamă parcurgerea obligatorie a unor etape din istoria sa, în caz contrar, creându-se „epoci vide” ştiinţific. Prin urmare, trebuie reluat firul cercetărilor ştiinţifice de acolo de unde a fost întrerupt. Unele reguli ale gramaticii sunt şi reguli ale logicii, dar cele două domenii nu-şi manifestă validitatea în mod identic. Unele construcţii lingvistice nu au nicio semnificaţie logică, iar unele structuri ale limbajului natural nu au nicio greşeală gramaticală, fiind o înşiruire de semne fără sens (ex. Calculatorul mănâncă biroul.). De asemenea , există structuri ireproşabile din punct de vedere logic, dar ele pot fi considerate ca fiind greşite din punct de vedere lingvistic. Conceptul de „regulă” se aseamănă cu cel de „normă”, reclamând unitatea dintre tot ceea ce este logic şi se supune lingvisticii. Cunoaşterea unui sistem de reguli este hotărâtoare pentru conceperea unui algoritm, aplicat ca metodă de cercetare în studiul limbii.
Dezvoltarea „limbajelor artificiale” care urmăresc evitarea complexităţii problemelor generate de studierea limbajelor naturale a impulsionat apariţia unor noi tipuri de gramatici. Din aceste motive, studiul limbilor naturale este un subiect deschis pentru construirea unor noi modele de gramatică ( în funcţie de specificul limbilor naturale şi al celor artificiale), identificarea formelor de manifestare ale gramaticalităţii şi precizarea similitudinilor dintre formele gramaticale şi cele logice ale limbajului natural.
Sistemele de prelucrare automată a textelor probează, totuşi, că limbile naturale nu sunt calcule, ci sisteme comunicaţionale deschise, care aplică nu atât relaţii uzuale, adică socialmente fixate ca stabile pentru semnificant şi semnificat în semn şi între diverse semne, cât un act semic secundar, adică asocieri ocazionale incalculabile pentru componentele (laturile) semnelor. De aceea, limbile naturale au o organizare neclară, pluridimensională şi continuativă şi aplică o logică vagă şi relaţii de toleranţă pentru elementele lor. Există opinii care neagă ipoteza epistemologică că activitatea verbal-mentală a omului şi întregul lui comportament ar fi pe deplin formalizabile în termenii unui sistem unic de reguli lingvistice.
1A. Danzin, Raport Special al Comisiei Europene, March, 1992, Towards a European Language Infrastructure, www.academiaromana.ro.
2Cf. Marius Sala, Ioana Vintilă Rădulescu, Limbile Europei, Editura Univers Enciclopedic, 2001, p.9 u.
3John Hutchins, Machine translation (computer-based translation), 11 January, 2006, www.eamt.org.
Bibliografie:
1. Academia Română, Limbaj şi tehnologie, Editura Academiei Române, Bucureşti, 1996.
2. Academia Română, Secţia de Ştiinţă şi Tehnologia Informaţiei, Institutul de Cercetare pentru Inteligenţă Artificială, Limba Română în Societatea Informaţională- Societatea Cunoaşterii, Coordonatori: Dan Tufiş, Florin Gh. Filip, Bucureşti, 2002.
3. Dimitriu, Rodica, Disocieri şi diferenţe în traductologie, Editura Timpul, Iaşi, 2001.
4. Drăgănescu, M., Societatea informaţională şi a cunoaşterii. Vectorii societăţii cunoaşterii, în Societatea Informaţională – Societatea Cunoaşterii. Concepte, soluţii şi strategii pentru România. Academia Română, Editura Expert, 2001
5. Jeanrenaud, Magda, Universaliile traducerii. Studii de traductologie, Polirom, Iaşi, 2006.
6. Sala, Marius, Răsulescu-Vintilă, Ioana, Limbile Europei, Univers Enciclopedic, Bucureşti, 2001.














Comentarii recente